
ROR matching service
At the start of the project, basic affiliation search functionality was implemented for Thieme, as provided by the ROR API. Our experience shows that this allows just over half of the affiliation text strings to be matched to an ROR ID, with reliable results. We observe a false positive rate of less than 0.5%, with at least 2 million matches.
For Thieme, this was insufficient, so we embarked on a project with this publisher to further improve our ROR matching service. In this case study, we describe all the steps taken.
-
When
2024 - 2026
-
Client Name
Thieme Verlag
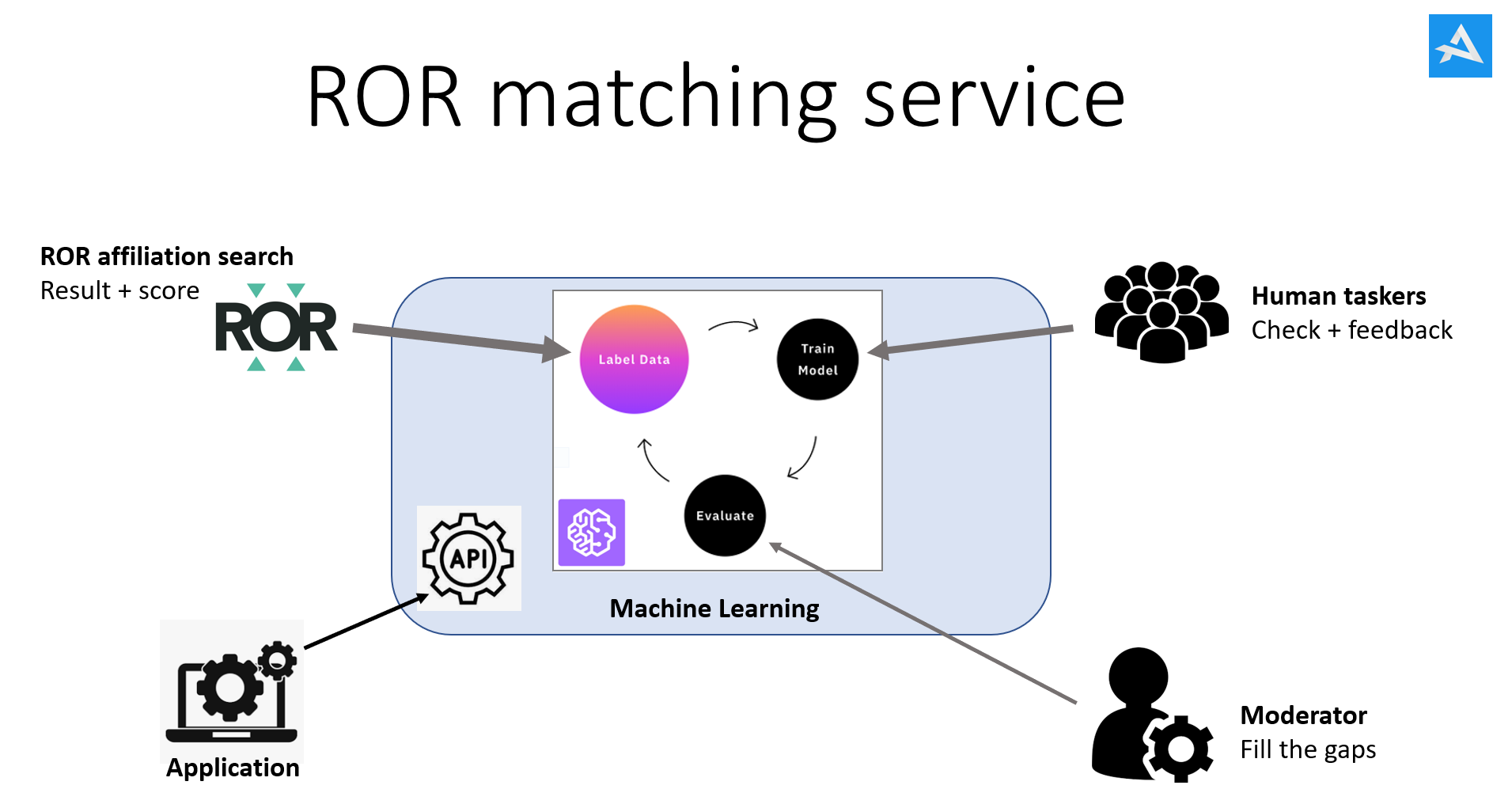
Components of the service
Interaction with the ROR API, specifically the affiliation search functionality, remains at the heart of the ROR matching service. As mentioned, this yields an indicative 52% match rate, which is reliable. However, for the remaining 48%, data is either returned or not, which in itself provides valuable information.
An initial addition we have made is to feed these non-matches to people. We bring humans into the loop, as it is known. Naturally, this is not entirely disconnected from the process, but rather fully integrated. For this purpose, Appetence developed a separate service, HITman, referring to HITs, or Human Intelligence Tasks. We currently support two types of HITs:
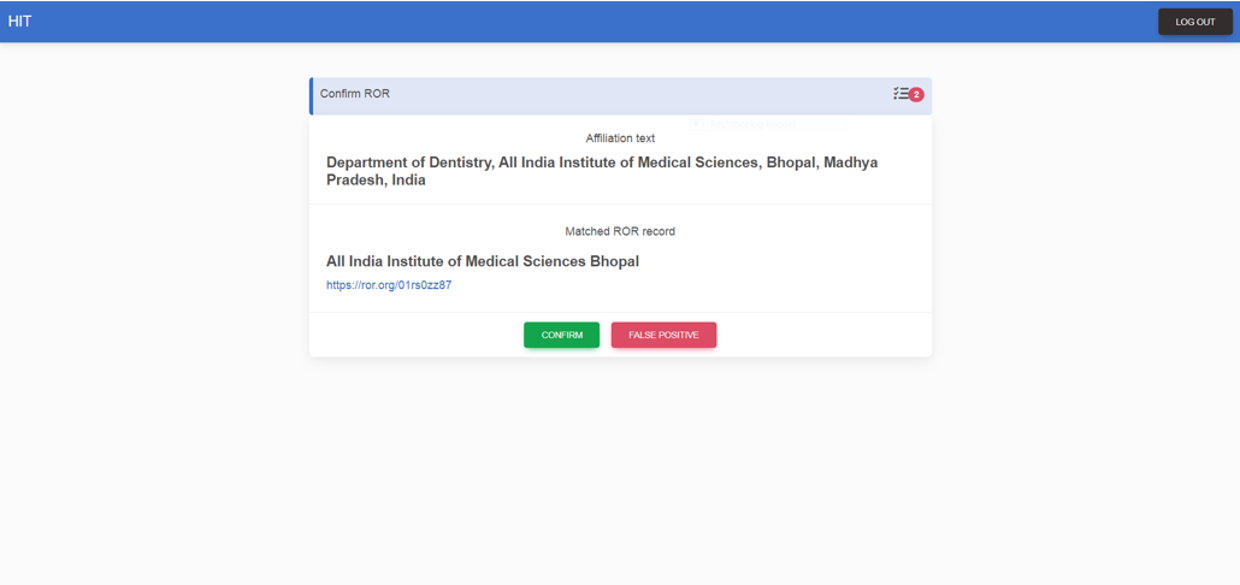
- A HIT where the human tasker must confirm or reject an ‘uncertain’ match. On our HITman platform, taskers can process up to 400 to 500 of these HITs per hour, at minimal cost.
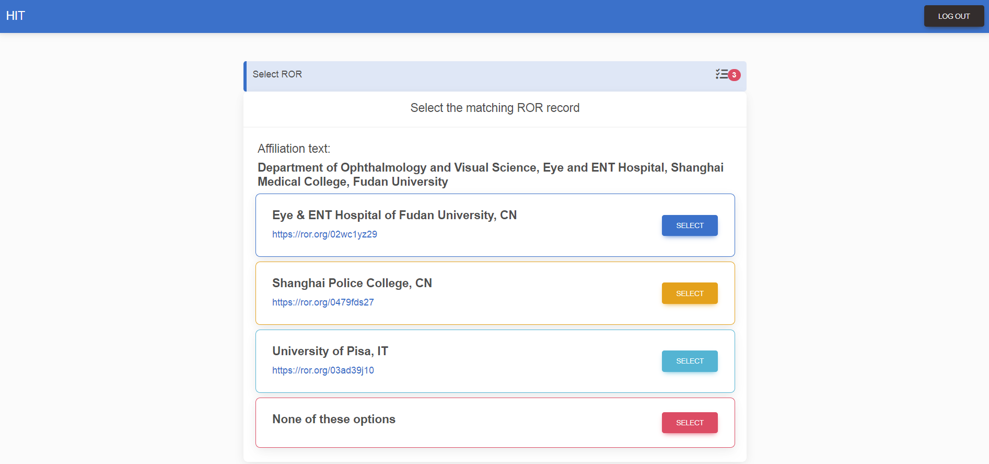
- A second type of HIT involves taskers selecting the correct match from a shortlist of possible matches, or not. These types of HITs are processed at a rate of 100 to 200 per hour, at a slightly higher cost.
The natural reaction we always get is: why don’t you use AI for this? There are a number of reasons for this.
- We do indeed use Machine Learning (ML) and Natural Language Processing (NLP), but such mechanisms are useless without data on which the ML can be trained. And that is precisely the data that comes from HIT. We use the HIT data for pre-training and re-training the ML/NLP model so that it can continuously improve. In AI terms, this is called reinforced learning.
- Uncertainty remains a significant factor in any AI application. The human-in-the-loop is crucial. We therefore also have the taskers moderate the AI results, and false positive data, for example, is particularly valuable for improving the ML.
In short, it is a collaboration between AI and humans, fully integrated into our ROR matching service.
With the advent of modern LLM technology – such as ChatGPT – we were able to take another step forward. Based on the ROR dataset, we developed our own vector search-based matching engine. This serves as an extension to the ML and NLP techniques. It delivers even better results. However, our proprietary vector search does not replace the ROR API search; rather, they operate in parallel and in conjunction with one another. A vector search clearly yields more matches, but the false positive rate also increases. In practice, we therefore use the vector search primarily to add certainty to the match results,
The result: what is possible?
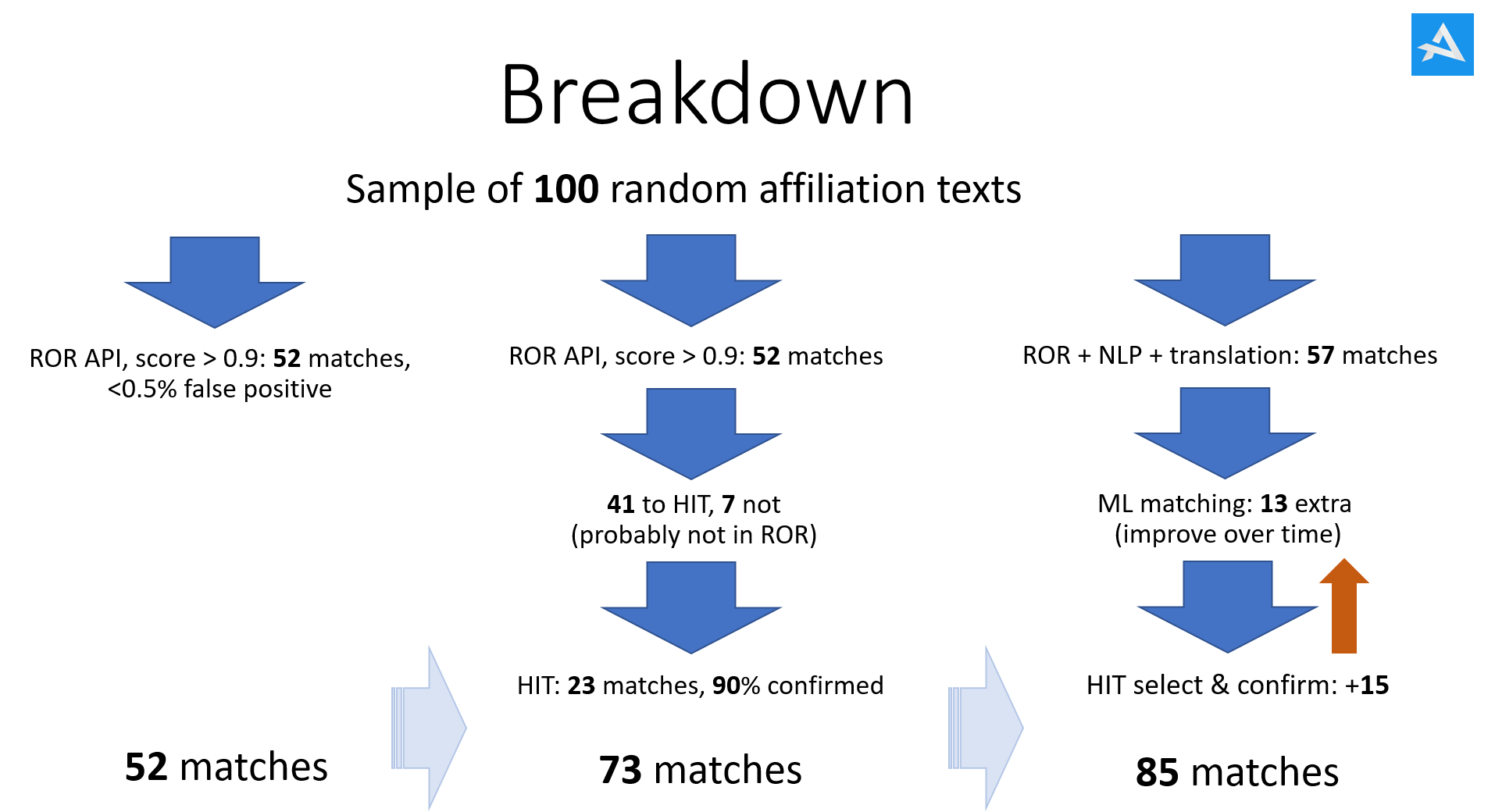
Of course, this depends on your own dataset. Thieme has many affiliations from Germany, which is considerably more difficult than, say, the Netherlands. If you have a lot of data from China, it is even more difficult. As mentioned, the baseline is roughly 52% matches with a high degree of certainty: <0.5% false positives. Incidentally, with 1 million matches, that still amounts to 5,000 ‘incorrect’ matches!
Using HIT increases the matching percentage to roughly 75%, whilst also improving reliability, although humans do make mistakes too, so it is not zero.
The combination of ML, NLP and vector search techniques (AI in general) increases the matching percentage to an average of around 85%, with peaks well above 90% on specific selections. This is explicitly in combination with HITs, not just AI.
And what about the rest? This again depends on the dataset, but roughly 40% of the non-matches are unusable; think, for example, of just the text ‘University Hospital’. Another portion, also around 40%, is correctly formatted but refers to a record that simply isn’t in ROR yet. Think, for example, of “Doctors Office Jansen in Amsterdam”. And the remaining 20% of the non-matches could potentially be matched with some extra manual effort, but the costs do not outweigh the benefits.